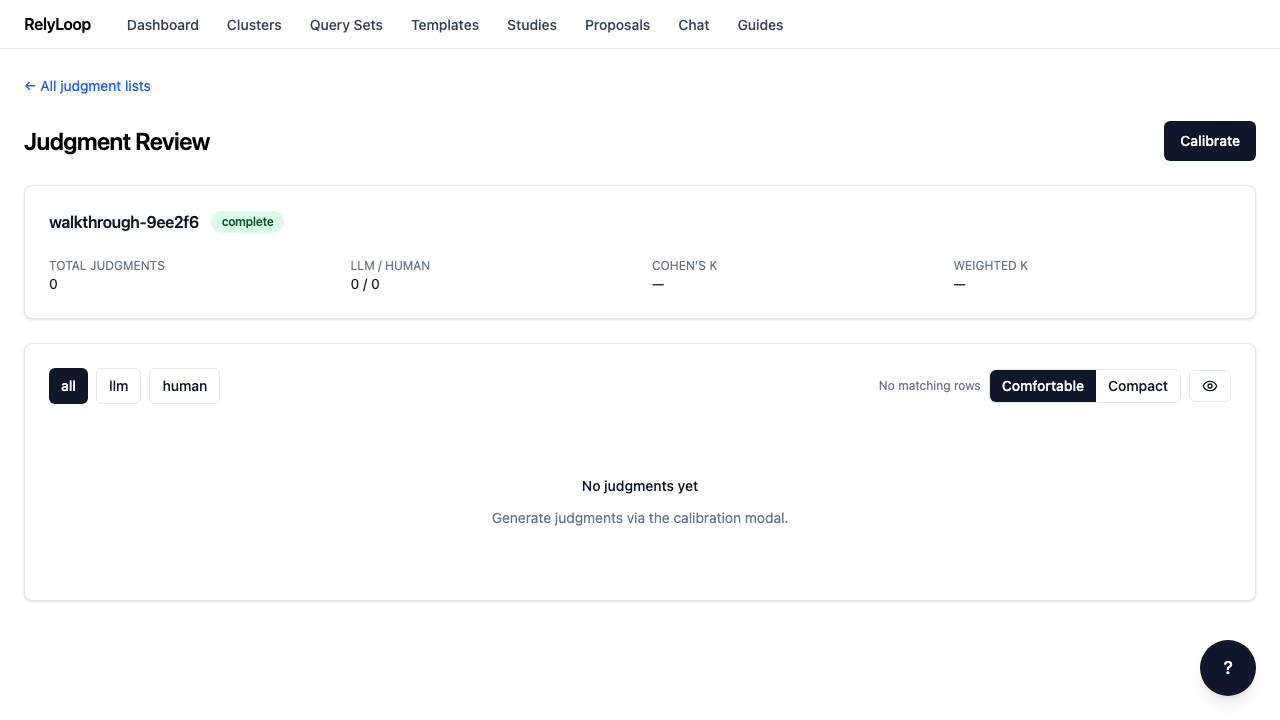
Generate judgments via LLM¶
About this walkthrough
Estimated time: 5 minutes (mostly waiting on the worker) Tags: judgments, llm, ground-truth
Trigger the LLM-as-judge worker against a query set — every (query, top-K doc) pair is rated 0-3 with a real OpenAI call. The deterministic alternative is the import path (guide 05).
Trouble playing? Download the walkthrough video.
Step 1 — Open a query set's detail page. The 'Associated…¶
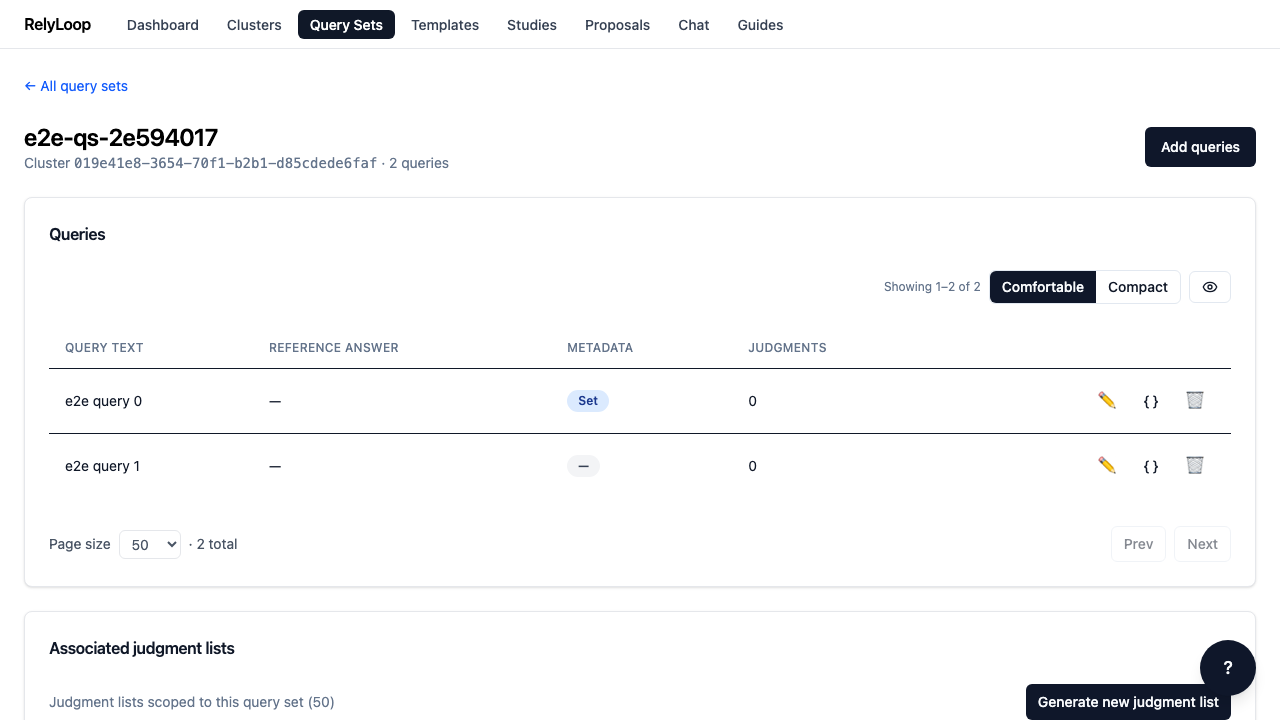
Step 2 — Click 'Generate judgments' to open the dialog. The…¶
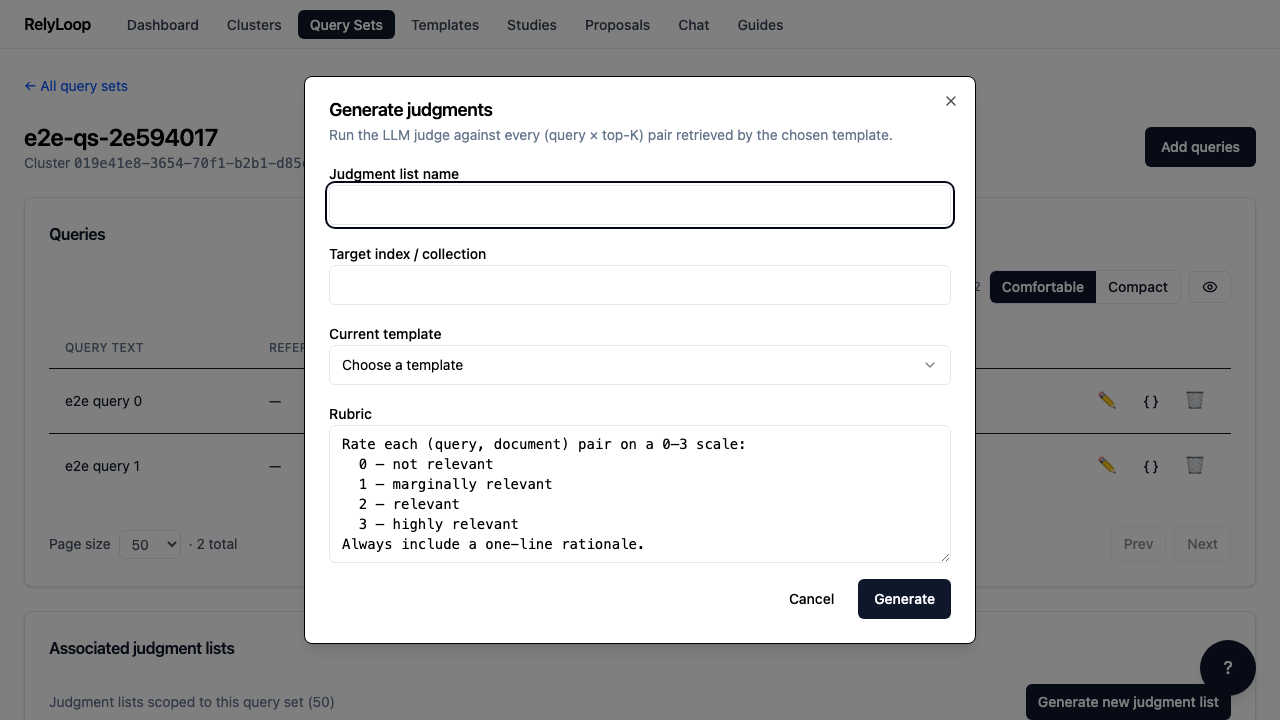
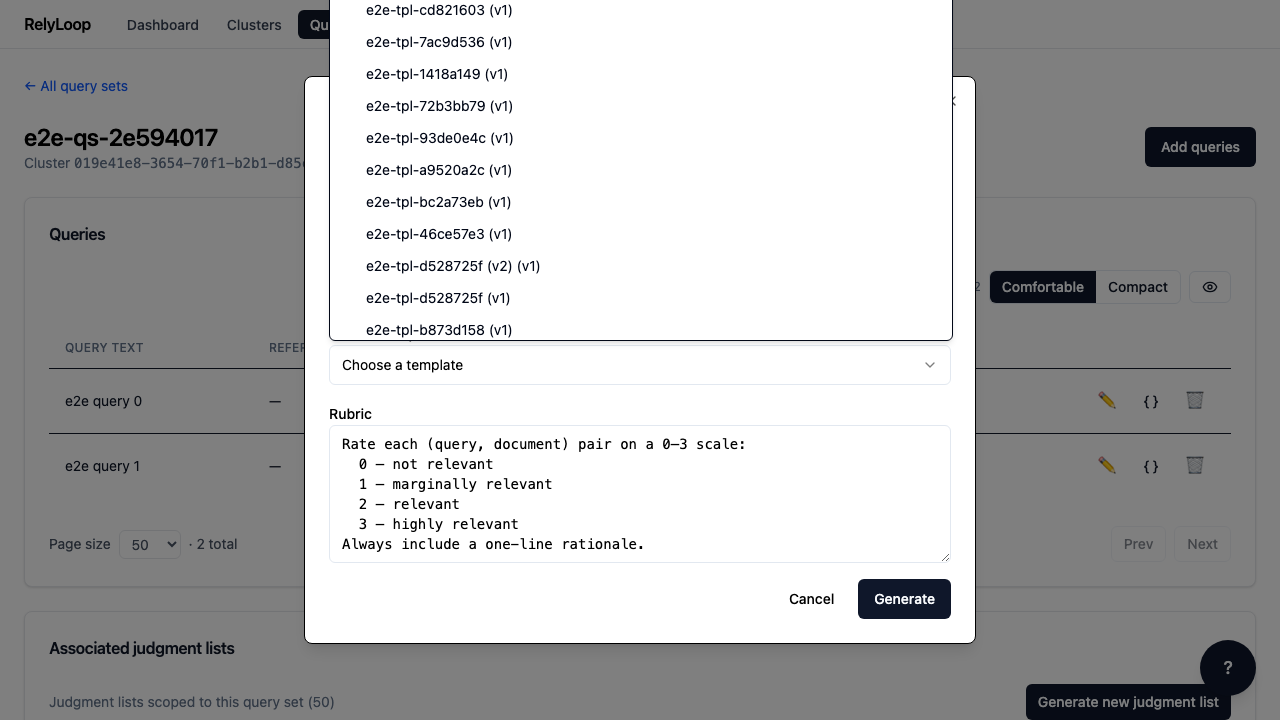
Step 3 — Fill the text fields: a unique name for…¶
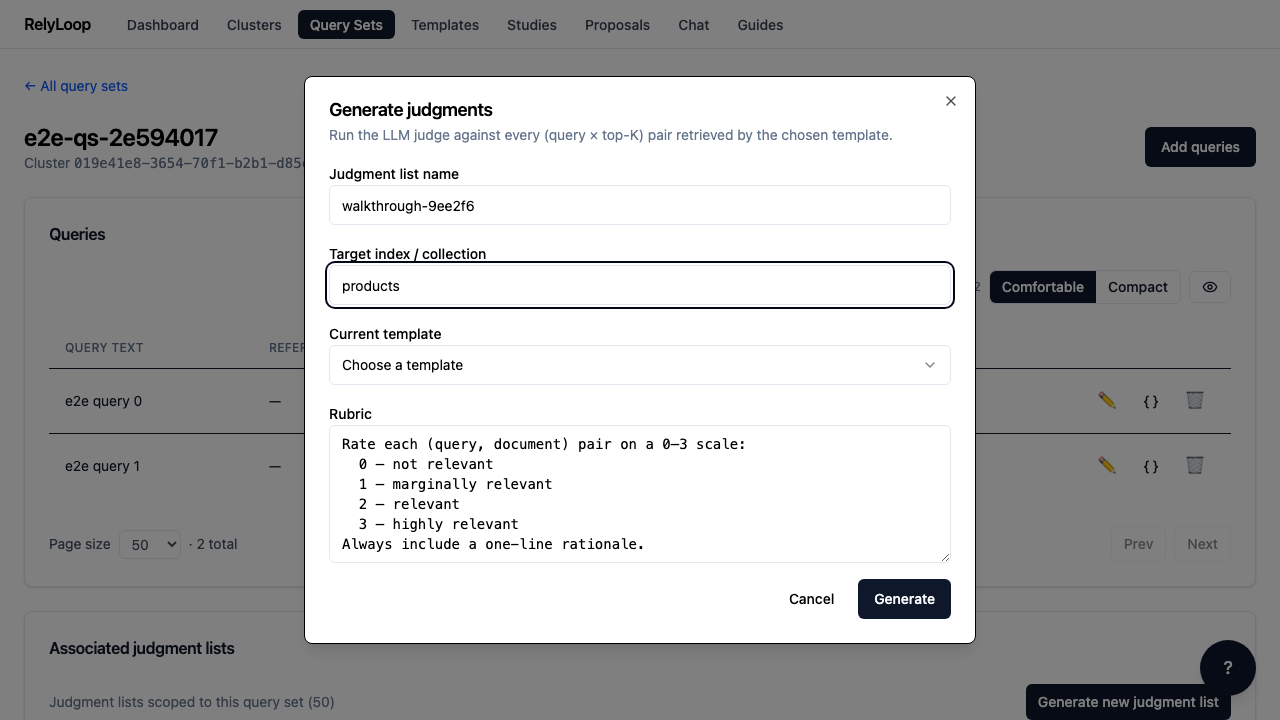
Step 4 — Open the template dropdown and pick the query…¶
Step 5 — Submit. The worker enqueues immediately (202 ACCEPTED) and…¶