Import judgments + calibrate¶
About this walkthrough
Estimated time: 3 minutes Tags: judgments, calibration, ground-truth
Skip LLM generation by importing pre-curated judgments, then run the kappa calibration to measure agreement against human ground truth.
Trouble playing? Download the walkthrough video.
Step 1 — Open a judgment list's detail page (/judgments/{id}). The…¶
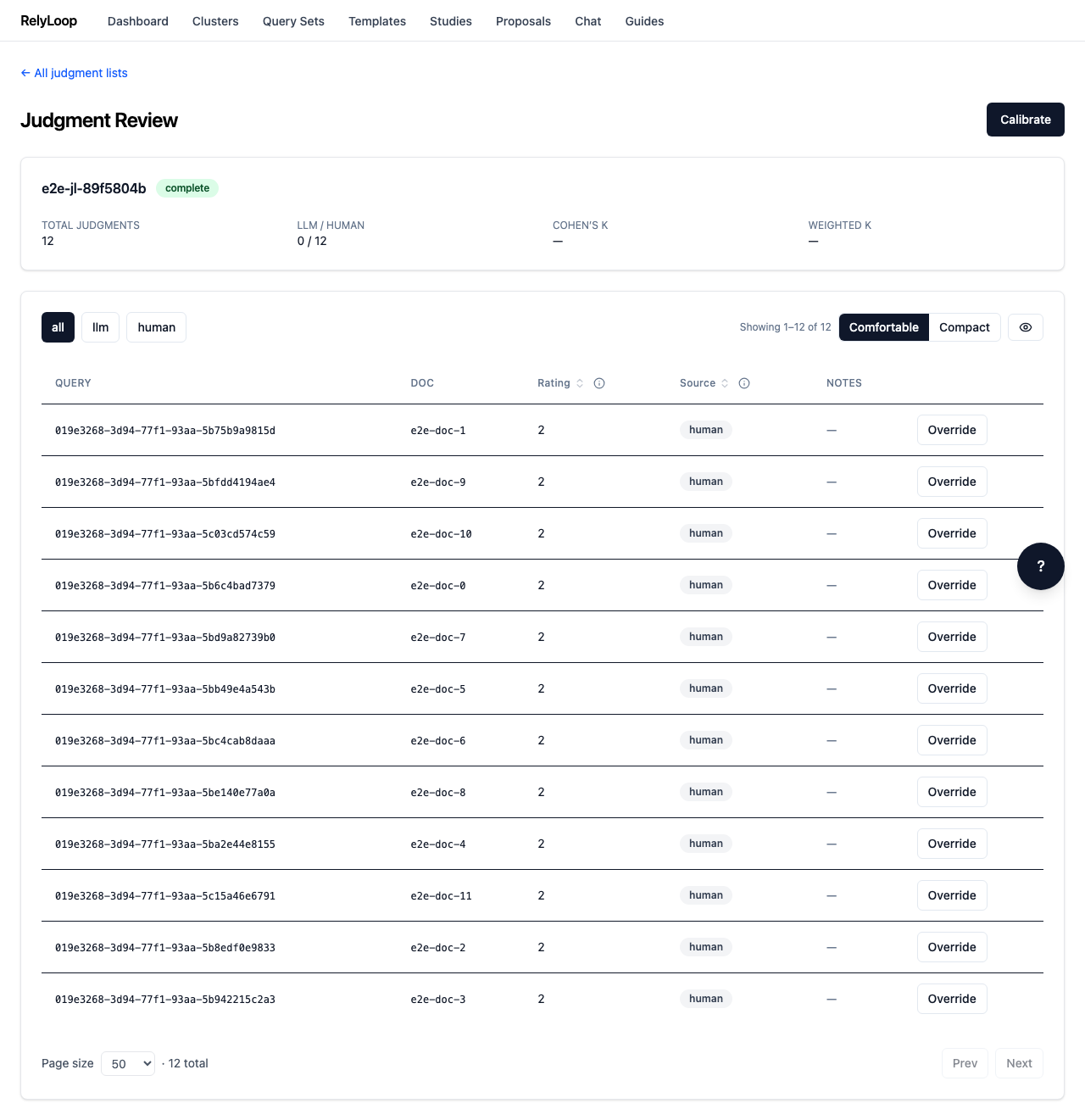
Step 2 — Click 'Calibrate' to open the kappa-computation modal. Calibration…¶
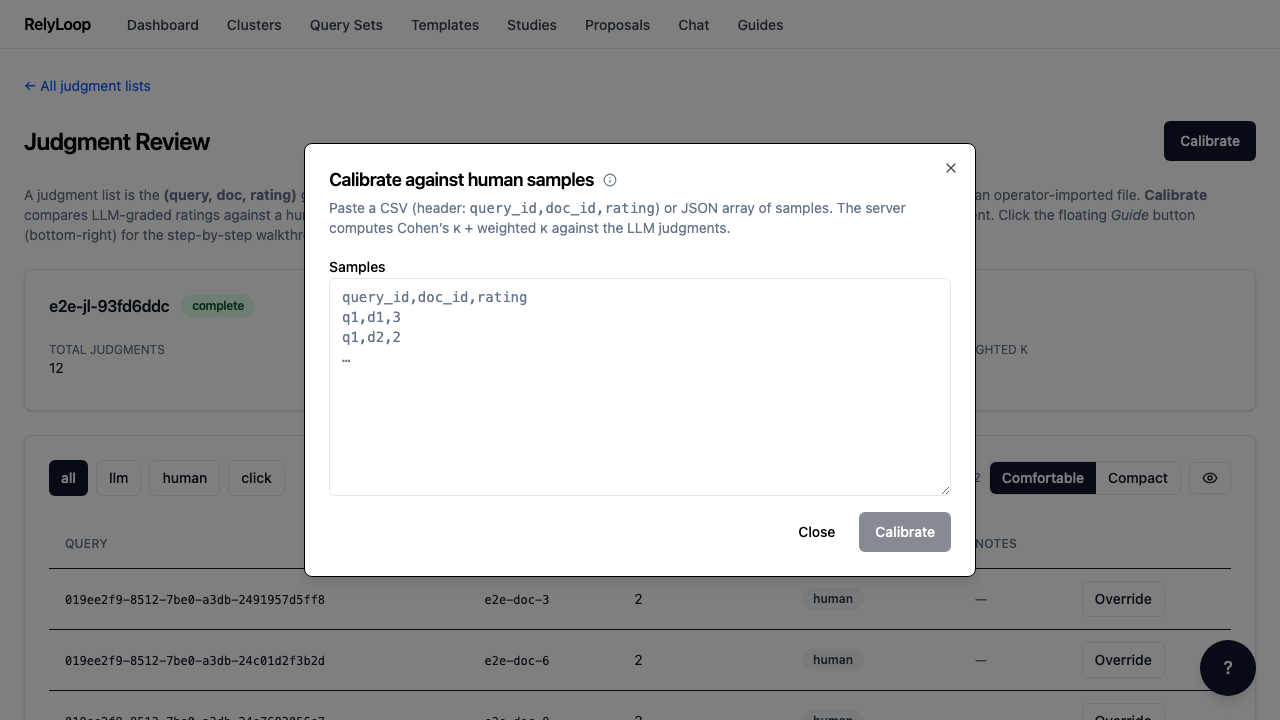
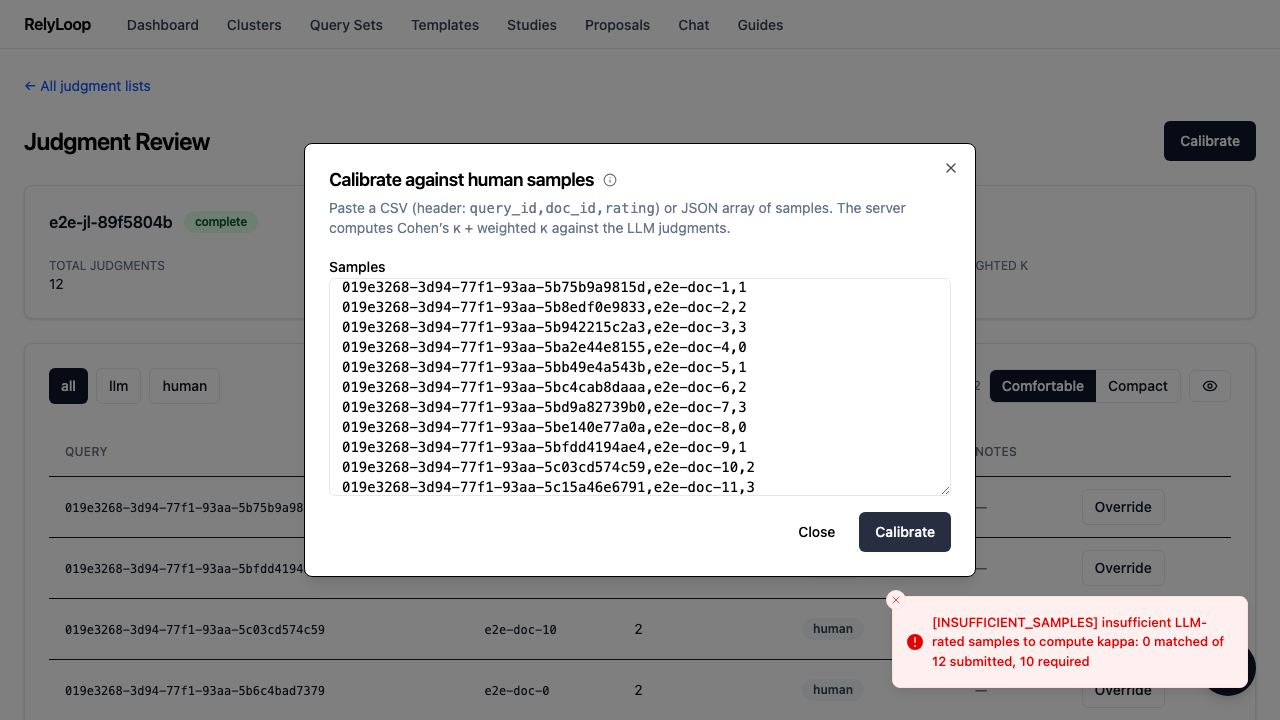
Step 3 — Paste a CSV of human-rated samples: query_id,doc_id,rating (header…¶
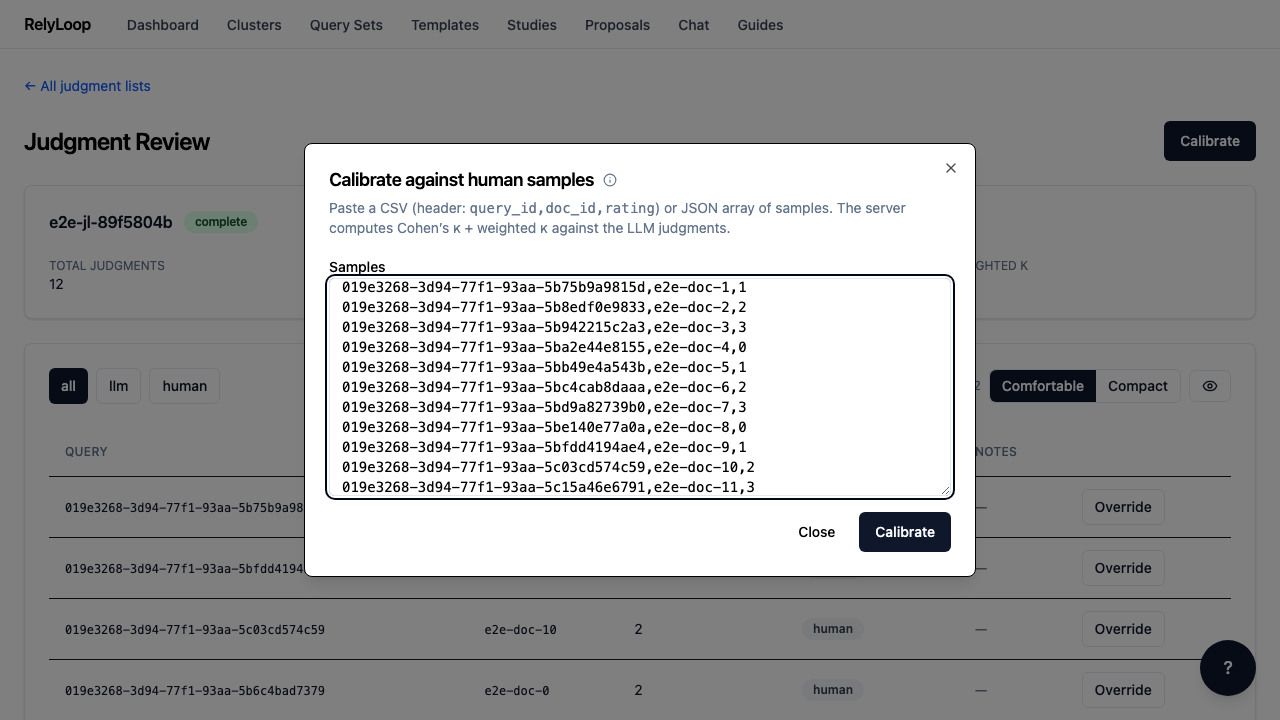
Step 4 — Submit. The result panel shows Cohen's kappa, linear-weighted…¶